Altera_Forum Honored Contributor
Honored Contributor
Honored ContributorHonored ContributorHonored ContributorHi Yann,
I did three measurements ... RC -> Endpoint IMEM read, Endpoint -> RC DDR3 read and finally RC -> Endpoint config register read. The final measurement was the reality check where I was reading a local register to the endpoint PCIe IP. This takes out any fabric and actual memory read time. From what I have been told, the latency can be from 100nS to 1uS .. that is probably for a high speed link. I was running Gen1 X1 and measured about 1uS and had full observability of when the Read request was received and when the Read completion started to be sent.... so for me I was able to decouple the actual link physical transport times. See attached image. Back to the third case of RC -> Endpoint config register read ... if the Hard IP is running at say 50 Mhz and the processing time is about 1uS, then 1000 nS/20nS = approx. 50 clocks . That would be 50 clocks to parse / check the TLP read command, get the register to be read, put it in an output queue, form the TLP for the Read Completion and send it to the PIPE I/F then have the PHY start to send it out. 50 clocks may be reasonable If the PCIe IP is running at 100 Mhz , then it would be 100 clocks which sounds alot for processing a read request. You can make some similar measurements .... to see. 2uS is on the high side ... is it a Read being processed by the RC ... in which case , try to make sure there is no contending "fabric" traffic. From a performance perspective, read latency by the RC is a factor ... one improvement is in the number of outstanding reads you can support. Best Regards, Bob.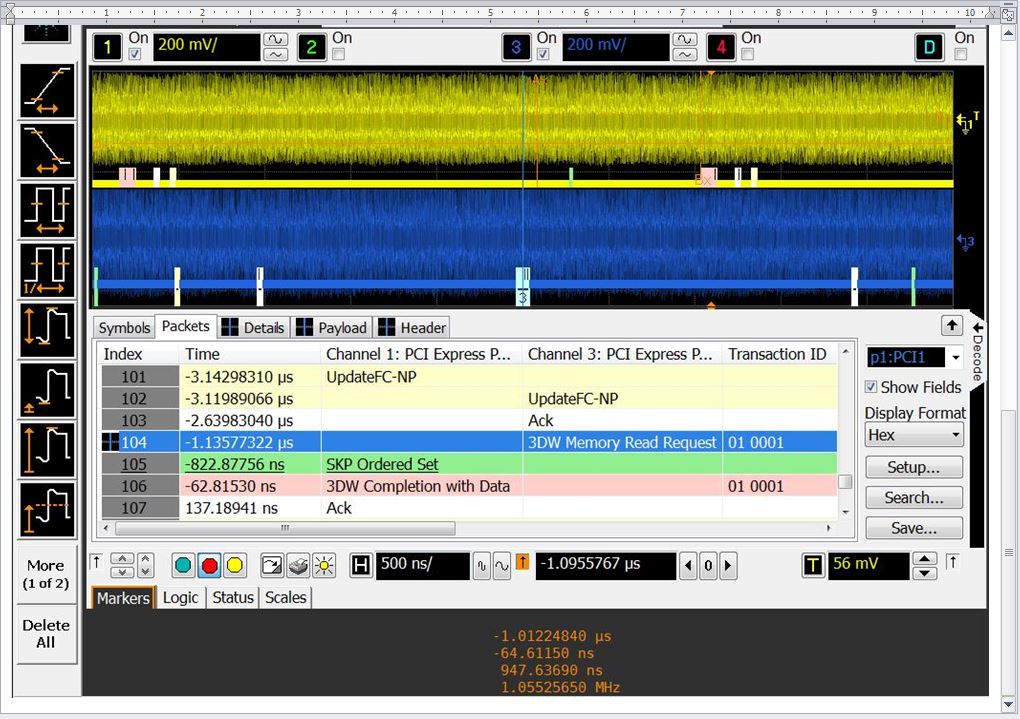{kind=link}